Did you know that you can navigate the posts by swiping left and right?
The path to LFCE Day1 : using Git
29 Jul 2020
. category:
linux
.
Comments
#linux
#lfce
Using a version control system (VCS)
Why use a VCS ?
Not using a VCS can lead to unnecessary complications when working in a team, for instance if a team member is working on a specific file then he will have to notify other members and ask them not to modify the same file until he’s done, which is a highly inefficient workflow. moreover, storing different versions of a file can become tedious very quickly and if we consider a project with thousands of files that are updated every day this becomes a nightmare.
VCS offers an easy way to store a changelog for the state of a project (changes on files) and enables multiple developers to work simultaneously on their local machines and merge the changes from all developers without big hassles.
What types of VCS are there?
there are mainly two types of version control systems, distributed and cetnralized.
centralized VCS use the client-server model where the server keeps one centralized repository of the code, it also uses locking mechanisms controlled by the server to ensure that only one developer is working on a piece of code at a particular time and the access is unlocked once the developer pushes his code to the central repository. examples of such systems include apache subrevision, Concurrent Versions System
distributed VCS work on a peer-to-peer model where a copy of the codebase and the history of changes made to the repository is kept on all developers machines, moreover there is no locking in this model developers can works on any parts of the code simultaneously and once done they can incorporate the changes to the master copy which kept in a client machine rather than a central server and is considered the final product that all developers will push their changes to. examples of distibuted VCS include Git, mercurial
The different copies of a repository
whatch the following video, it does a great job explaining the different copies and states of a repository. https://www.youtube.com/watch?v=3a2x1iJFJWc
Hands on
creat and initialize a git repository, we’re strating off with an empty hoe directory
mheni@host01:~$ cd
mheni@host01:~$ pwd
/home/mheni
mheni@host01:~$ ls
git init creates the directory for the repo and initializes it with a hidden folder .git
mheni@host01:~$ git init testRepo
Initialized empty Git repository in /home/mheni/testRepo/.git/
mheni@host01:~$ ls
testRepo
mheni@host01:~$ ls -a testRepo/
. .. .git
mheni@host01:~$ ls -a testRepo/.git/
. .. branches config description HEAD hooks info objects refs
now we can start adding files, we are just creating a file and adding some content to it
mheni@host01:~$ cd testRepo/
mheni@host01:~/testRepo$ echo "Salt-N-Pepa" > file1
mheni@host01:~/testRepo$ echo "push it" >> file1
mheni@host01:~/testRepo$
now we can check the status of our repo with git status, which shows that file1 is untracked meaning that we’ve added the file to our working directory but not to the staging area.
mheni@host01:~/testRepo$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
file1
nothing added to commit but untracked files present (use "git add" to track)
we need to use git add in order to stage the file, checking the status again shows that file1 is now tracked and we can commit it to the local repository.
mheni@host01:~/testRepo$ git add *
mheni@host01:~/testRepo$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: file1
we need to setup our username and email before we can commit.
$ git config --global user.name "mheniMerz"
$ git config --global user.email "mheni.merzouki@nist.gov"
$ git commit -m "first commit"
[master (root-commit) f48a02e] first commit
1 file changed, 2 insertions(+)
create mode 100644 file1
$
push it, and don’t forget to setup a remote repo first we will use github to create a remote repo
next we will set up the remote repository for our local repository, for that we need copy the link from github
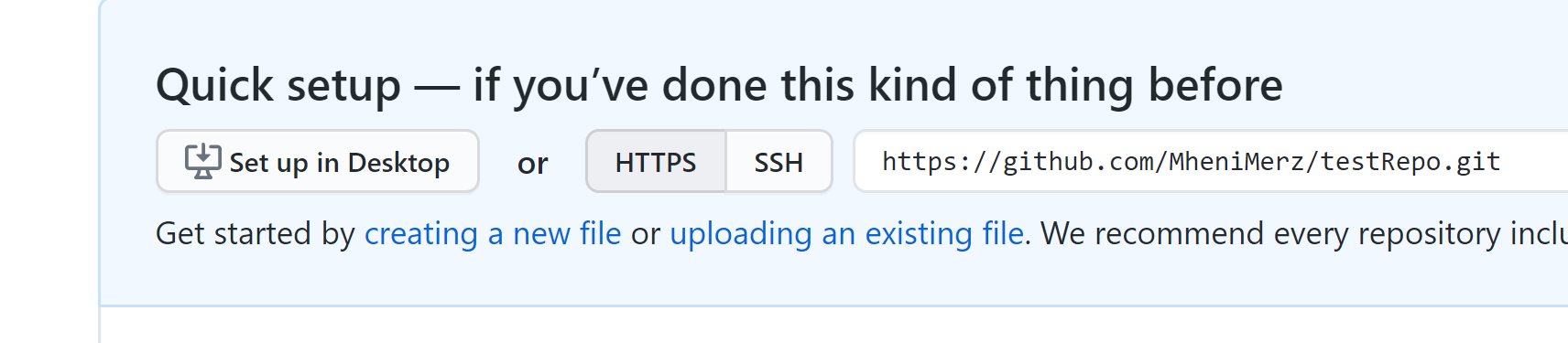
now we can set up the remote repo and push our “code”.
$ git remote add origin https://github.com/MheniMerz/testRepo.git
$ git push origin master
Username for 'https://github.com': mheniMerz
Password for 'https://mheniMerz@github.com':
Enumerating objects: 3, done.
Counting objects: 100% (3/3), done.
Writing objects: 100% (3/3), 230 bytes | 230.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/MheniMerz/testRepo
* [new branch] master -> master
create another user, update file, commit, push
we will simulate a colleague by creating a new user and have him download the repo and modify it, we use $ adduser user2 to create the user.
switch to user2 $ su - user2 and move to the home directory $ cd ~.
now we can clone the remote repo.
user2@host01:~$ git clone https://github.com/MheniMerz/testRepo
Cloning into 'testRepo'...
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 3 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), 210 bytes | 210.00 KiB/s, done.
user2@host01:~$ cd testRepo/
user2@host01:~/testRepo$ git status
On branch master
Your branch is up to date with 'origin/master'.
nothing to commit, working tree clean
We will add a second file.
user2@host01:~/testRepo$ echo "The section - Fork it over" > file2
user2@host01:~/testRepo$ git status
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
file2
nothing added to commit but untracked files present (use "git add" to track)
user2@host01:~/testRepo$
commit and push.
user2@host01:~/testRepo$ git add *
user2@host01:~/testRepo$ git commit -m "add file2"
[master 5ed7705] add file2
1 file changed, 1 insertion(+)
create mode 100644 file2
user2@host01:~/testRepo$ git status
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
nothing to commit, working tree clean
before pushing our modifications we can check how different is the remote repo from our local repo. we can see that our local repo has new changes (is ahead of the remote repo) so we can go ahead and push it
user2@host01:~/testRepo$ git diff origin master
diff --git a/file2 b/file2
new file mode 100644
index 0000000..e89c9e4
--- /dev/null
+++ b/file2
@@ -0,0 +1 @@
+The section - Fork it over
user2@host01:~/testRepo$
we can push it with the same command as before, note that the remote link is already setup because we cloned the repo instead of initialzing it.
user2@host01:~/testRepo$ git push origin master
Username for 'https://github.com': mheniMerz
Password for 'https://mheniMerz@github.com':
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 2 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 288 bytes | 288.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/MheniMerz/testRepo
f48a02e..5ed7705 master -> master
user2@host01:~/testRepo$ git diff master origin
user2@host01:~/testRepo$
pull updates from remote repo to local repo, now we need to goack to the other user exit, and check the difference between his local repo and the remote repo
mheni@host01:~/testRepo$ git diff master origin
diff --git a/file2 b/file2
new file mode 100644
index 0000000..e89c9e4
--- /dev/null
+++ b/file2
@@ -0,0 +1 @@
+The section - Fork it over
so we need to download the latest updates to out local repository.
mheni@host01:~/testRepo$ git pull
remote: Enumerating objects: 2, done.
remote: Counting objects: 100% (2/2), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 2 (delta 3), reused 1 (delta 0), pack-reused 0
Unpacking objects: 100% (2/2), done.
From https://github.com/MheniMerz/testRepo
f48a02e..5ed7705 master -> origin/master
Updating f48a02e..5ed7705
mheni@host01:~/testRepo$ git diff master origin
mheni@host01:~/testRepo$
Flashcards
Why do we need to use a version control system?
because the alternative is to create a new file for each change (new version) and that can get overwhelming very quickly. version control systems enable us to access the changelog of a file easily.
what is Git?
Git is a distributed version control system, meaning that all users access to the changelog and they have a copy of the repository on their systems instead of the code being stored in one central server.
how do we initialize a repo? and, what does it do?
~$git init [directory]
`git init` enables git to start tracking the repo for future changes to be done.
how to add tracking for a new file?
`~$git add [filename]` or `~$git add *` to add all files.
how to commit a change? and what does it mean?
`~$git commit -m "message explaining the updates"`
`~$git commit -a -m "message "` ==> add and commit
`~$git commit -m "message" [file1] [file2]` ==> commit specific files.